> ## Documentation Index
> Fetch the complete documentation index at: https://docs.osto.one/llms.txt
> Use this file to discover all available pages before exploring further.
# WAF Availability & Uptime
> How Osto keeps your Web App & API Protection (WAF) layer online — our uptime target, how we measure it, the architecture behind it, and how we respond to incidents.
Osto's Web App & API Protection (WAF) sits inline, in front of every request — so its availability is your availability. Here's the uptime we target for the protection layer, how we measure it, and the architecture that keeps your site online. Backed by numbers, not adjectives.
The monthly uptime we target for the Osto protection layer, measured honestly.
A reverse proxy that inspects every request and forwards clean traffic to your origin.
Real-time monitoring of the protection infrastructure, every minute of every day.
DDoS floods, bad bots, and OWASP-class attacks are filtered before they reach your origin.
**We target 99.9% monthly uptime for the Osto protection layer.** Need it in writing?
We're happy to put a contractual SLA with service credits in your agreement — just
[talk to us](mailto:connect@osto.one).
## Our uptime target
We target **99.9% monthly availability** for the Osto protection layer — the reverse proxy that inspects your traffic and forwards clean requests to your origin. It's a number we stand behind and measure honestly, so you get real availability you can plan around.
Here's what different availability levels mean in concrete terms:
| Availability | Downtime per month | Downtime per year | |
| ----------------------- | ------------------ | ----------------- | - |
| 99% | \~7.2 hours | \~3.65 days | |
| **99.9% — Osto target** | **\~43.8 minutes** | **\~8.8 hours** | ✅ |
| 99.95% | \~21.9 minutes | \~4.4 hours | |
| 99.99% | \~4.4 minutes | \~52.6 minutes | |
The target covers the Osto protection layer accepting, inspecting, and forwarding your
traffic. Your own origin's uptime is a separate layer — and Osto helps you keep that
online too, with redundant origins and real-time health alerts (see
[How we keep you online](#how-we-keep-you-online)).
## How we measure uptime
A number is only as good as its method, so here's ours:
* **Window** — availability is measured per calendar month.
* **Sampling** — the protection layer is health-checked continuously, and availability is averaged across those checks over the month rather than judged on a single snapshot.
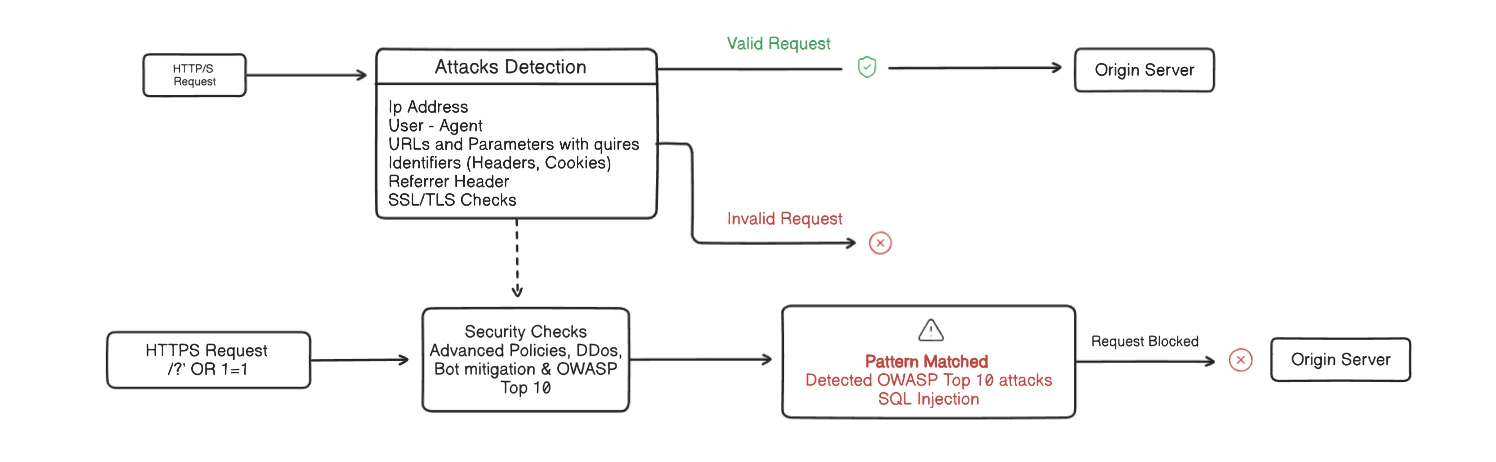
* **The formula** — `Availability = (total minutes in the month − minutes unavailable) ÷ total minutes in the month`.
* **What "unavailable" means** — a request to a healthy origin cannot be accepted, inspected, and forwarded by the Osto protection layer.
* **What we watch** — Osto continuously monitors the protection infrastructure in real time. When you're signed in, the live **All Systems Operational** indicator in the dashboard reflects that monitoring.
## What the target covers
We measure availability fairly: the target covers what Osto controls — the protection layer — and sets clear expectations so there's never a question during an incident.
| Counts toward the Osto target | Sits outside it |
| -------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------ |
| The protection layer accepting and forwarding requests to a healthy origin | Your **origin server** being down, overloaded, or returning errors |
| Osto proxying clean traffic without error | **DNS** not yet pointed at Osto, or a change still propagating |
| Osto's infrastructure inspecting every request | **Configuration** on your side (e.g. a policy or origin set incorrectly) |
| | Events beyond anyone's control (**force majeure**, third-party networks) |
| | **Scheduled maintenance** announced in advance (see [Planned maintenance](#planned-maintenance)) |
Osto helps you stay on top of the "outside it" column too — redundant origins and [WAF Upstream Health Alerts](#how-we-keep-you-online) catch origin problems early, and [Shared responsibility](#shared-responsibility) lays out who owns what.
## How we keep you online
The uptime target is backed by design. Every request flows through Osto as a high-performance reverse proxy that's built to keep serving traffic even when parts of the system — or your own origin — fail.
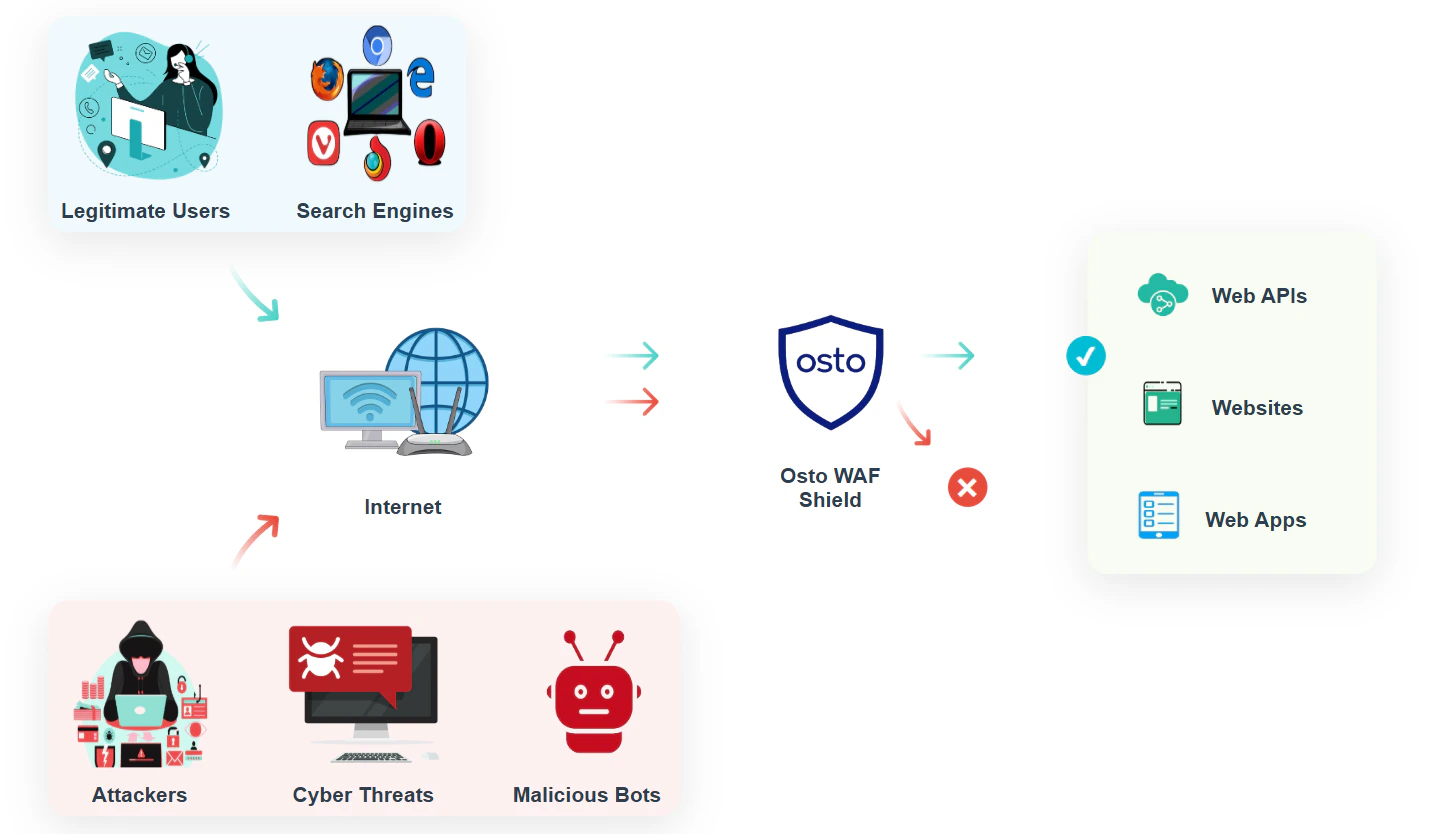 The protection layer runs across independent, health-checked capacity, so a fault in
any single component reroutes automatically instead of taking your site down.
When you register a website you can add **two *Server IP or LB Domain* entries** — the
second gives Osto a healthy backend to route to if the first becomes unreachable, so
your site stays up.
**WAF Upstream Health Alerts** notify you in real time the moment an origin server goes
down — so you know before your users do.
Dual-layer TLS keeps both legs encrypted — user-to-Osto and Osto-to-origin. The free,
auto-generated certificate is issued in minutes and renewed automatically before it
expires, so certificate expiry is one less thing to worry about.
## Staying up under attack
For a WAF, "available" and "under attack" are the same moment — and keeping you online through an attack is exactly what the protection layer is built for.
* **DDoS Protection** is on by default, absorbing volumetric and application-layer floods before they reach your origin. For the largest, most targeted campaigns, our team works alongside you with a tailored response.
* **Bot Mitigation** blocks automated abuse — scraping, credential stuffing, and brute-force attempts — that would otherwise exhaust your origin.
* **OWASP Top 10 protection**, virtual patching, and API protection stop injection, cross-site scripting, path traversal, and schema abuse before they land.
New domains can start in **Detect Mode**, which observes and logs threats without
blocking, so you can validate traffic patterns with zero risk to availability before
switching to **Prevent Mode**. It's the safest way to onboard a production site.
The protection layer runs across independent, health-checked capacity, so a fault in
any single component reroutes automatically instead of taking your site down.
When you register a website you can add **two *Server IP or LB Domain* entries** — the
second gives Osto a healthy backend to route to if the first becomes unreachable, so
your site stays up.
**WAF Upstream Health Alerts** notify you in real time the moment an origin server goes
down — so you know before your users do.
Dual-layer TLS keeps both legs encrypted — user-to-Osto and Osto-to-origin. The free,
auto-generated certificate is issued in minutes and renewed automatically before it
expires, so certificate expiry is one less thing to worry about.
## Staying up under attack
For a WAF, "available" and "under attack" are the same moment — and keeping you online through an attack is exactly what the protection layer is built for.
* **DDoS Protection** is on by default, absorbing volumetric and application-layer floods before they reach your origin. For the largest, most targeted campaigns, our team works alongside you with a tailored response.
* **Bot Mitigation** blocks automated abuse — scraping, credential stuffing, and brute-force attempts — that would otherwise exhaust your origin.
* **OWASP Top 10 protection**, virtual patching, and API protection stop injection, cross-site scripting, path traversal, and schema abuse before they land.
New domains can start in **Detect Mode**, which observes and logs threats without
blocking, so you can validate traffic patterns with zero risk to availability before
switching to **Prevent Mode**. It's the safest way to onboard a production site.
 ## Real-time monitoring & incident response
Staying available is about prevention *and* how quickly and openly we respond.
* **Continuous monitoring.** The protection infrastructure is monitored in real time, 24/7. The dashboard's **All Systems Operational** indicator reflects that live monitoring whenever you're signed in.
* **Proactive alerts.** WAF Upstream Health Alerts surface origin problems the moment they happen, and every request — allowed or blocked — is written to your **Web App Logs** for investigation.
* **Human response.** During an incident, reach the team at [connect@osto.one](mailto:connect@osto.one). Your agreement can include named response-time targets by severity.
* **Clear communication.** When an incident affects the protection layer, we tell you what happened and what we're doing about it — before you have to ask.
Today you can see live protection-layer status right in your dashboard, and we notify
you directly about any incident that affects your domains. A public, independently
hosted status page is coming soon to make that history visible outside the dashboard
too.
## Planned maintenance
Improvements to the protection layer are designed to ship without taking your traffic offline. When a change does need a maintenance window:
* We schedule it during low-traffic periods and announce it in advance.
* Maintenance windows announced ahead of time don't count against the uptime target.
* Provisioning and renewal of the auto-generated certificate are automated, so routine SSL work on it never needs a maintenance window or a manual step from you.
## Shared responsibility
Keeping your site online is a partnership. Drawing the line clearly means no surprises during a real incident.
| Osto keeps up | You keep up |
| -------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------ |
| Availability and capacity of the protection layer | Your **origin server**, healthy and reachable |
| Inspecting traffic and filtering DDoS, bots, and OWASP-class attacks | **DNS** pointed at Osto, with current records |
| Issuing and renewing the **auto-generated** SSL certificate | Renewing any certificate you upload yourself, and valid **policy and origin configuration** per domain |
| Monitoring the infrastructure and alerting you to origin health | Acting on **WAF Upstream Health Alerts** and log findings |
Two quick wins for your own resilience: add a **second origin** when you register a
website, and keep a **low DNS TTL** (around 600 seconds) so failover and routing changes
take effect quickly.
## Availability FAQ
No. The protection layer runs across redundant, health-checked capacity, so a fault in
a single component reroutes rather than taking your site down. On your side, register a
**second *Server IP or LB Domain*** so Osto always has a healthy backend to route to,
and turn on **WAF Upstream Health Alerts** to be notified the moment an origin goes
unhealthy. Have specific failover requirements for a domain?
[Contact us](mailto:connect@osto.one) and we'll tailor them to your setup.
Osto has you covered on both sides: add a second origin for high availability so Osto
can route around a failed backend, and **WAF Upstream Health Alerts** notify you in
real time so you can respond before users are affected.
Yes. 99.9% is our standing operational target, and when you need it in writing we'll
put a contractual SLA with service credits in your agreement. Where a documented SLA
applies, its terms are the source of truth. [Talk to us](mailto:connect@osto.one) for
terms.
No — keeping you online through an attack is exactly what the protection layer is for.
DDoS Protection is on by default and filters floods before they reach your origin, and
for the most targeted campaigns our team works with you directly.
Reach out at [connect@osto.one](mailto:connect@osto.one). We'll walk through the SLA
terms, service credits, and support response targets available for your plan and put
them in your agreement.
## Independently audited controls
Osto runs on the same platform we sell, and that platform's security and operational controls are independently audited — **SOC 2 Type II** and **ISO 27001** certified. These attest to how we build and run the service; reports are available to prospects and customers on request.
## Related
How the reverse-proxy protection model safeguards your applications and APIs.
Register a domain, add redundant origins, and choose Detect or Prevent mode.
Review threats, access, and policy violations for your protected domains.
***
Last updated: 2 July 2026. This page describes Osto's operational availability target and architecture for the Web App & API Protection layer. Where your agreement includes a documented SLA, that agreement's terms govern.
## Real-time monitoring & incident response
Staying available is about prevention *and* how quickly and openly we respond.
* **Continuous monitoring.** The protection infrastructure is monitored in real time, 24/7. The dashboard's **All Systems Operational** indicator reflects that live monitoring whenever you're signed in.
* **Proactive alerts.** WAF Upstream Health Alerts surface origin problems the moment they happen, and every request — allowed or blocked — is written to your **Web App Logs** for investigation.
* **Human response.** During an incident, reach the team at [connect@osto.one](mailto:connect@osto.one). Your agreement can include named response-time targets by severity.
* **Clear communication.** When an incident affects the protection layer, we tell you what happened and what we're doing about it — before you have to ask.
Today you can see live protection-layer status right in your dashboard, and we notify
you directly about any incident that affects your domains. A public, independently
hosted status page is coming soon to make that history visible outside the dashboard
too.
## Planned maintenance
Improvements to the protection layer are designed to ship without taking your traffic offline. When a change does need a maintenance window:
* We schedule it during low-traffic periods and announce it in advance.
* Maintenance windows announced ahead of time don't count against the uptime target.
* Provisioning and renewal of the auto-generated certificate are automated, so routine SSL work on it never needs a maintenance window or a manual step from you.
## Shared responsibility
Keeping your site online is a partnership. Drawing the line clearly means no surprises during a real incident.
| Osto keeps up | You keep up |
| -------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------ |
| Availability and capacity of the protection layer | Your **origin server**, healthy and reachable |
| Inspecting traffic and filtering DDoS, bots, and OWASP-class attacks | **DNS** pointed at Osto, with current records |
| Issuing and renewing the **auto-generated** SSL certificate | Renewing any certificate you upload yourself, and valid **policy and origin configuration** per domain |
| Monitoring the infrastructure and alerting you to origin health | Acting on **WAF Upstream Health Alerts** and log findings |
Two quick wins for your own resilience: add a **second origin** when you register a
website, and keep a **low DNS TTL** (around 600 seconds) so failover and routing changes
take effect quickly.
## Availability FAQ
No. The protection layer runs across redundant, health-checked capacity, so a fault in
a single component reroutes rather than taking your site down. On your side, register a
**second *Server IP or LB Domain*** so Osto always has a healthy backend to route to,
and turn on **WAF Upstream Health Alerts** to be notified the moment an origin goes
unhealthy. Have specific failover requirements for a domain?
[Contact us](mailto:connect@osto.one) and we'll tailor them to your setup.
Osto has you covered on both sides: add a second origin for high availability so Osto
can route around a failed backend, and **WAF Upstream Health Alerts** notify you in
real time so you can respond before users are affected.
Yes. 99.9% is our standing operational target, and when you need it in writing we'll
put a contractual SLA with service credits in your agreement. Where a documented SLA
applies, its terms are the source of truth. [Talk to us](mailto:connect@osto.one) for
terms.
No — keeping you online through an attack is exactly what the protection layer is for.
DDoS Protection is on by default and filters floods before they reach your origin, and
for the most targeted campaigns our team works with you directly.
Reach out at [connect@osto.one](mailto:connect@osto.one). We'll walk through the SLA
terms, service credits, and support response targets available for your plan and put
them in your agreement.
## Independently audited controls
Osto runs on the same platform we sell, and that platform's security and operational controls are independently audited — **SOC 2 Type II** and **ISO 27001** certified. These attest to how we build and run the service; reports are available to prospects and customers on request.
## Related
How the reverse-proxy protection model safeguards your applications and APIs.
Register a domain, add redundant origins, and choose Detect or Prevent mode.
Review threats, access, and policy violations for your protected domains.
***
Last updated: 2 July 2026. This page describes Osto's operational availability target and architecture for the Web App & API Protection layer. Where your agreement includes a documented SLA, that agreement's terms govern.